

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 라즈베리파이
- 유니티
- 날짜
- IOS
- PyQt
- ASP
- urllib
- Unity
- MS-SQL
- python
- Excel
- flutter
- 다이어트
- 리눅스
- javascript
- GIT
- 함수
- pandas
- Linux
- 맛집
- tensorflow
- ubuntu
- PyQt5
- mssql
- PER
- MySQL
- swift
- sqlite
- port
- node.js
목록BeautifulSoup (4)
아미(아름다운미소)
 python3 beautifulsoup 한글 깨짐
python3 beautifulsoup 한글 깨짐
soup = BeautifulSoup(html, "html.parser") soup = BeautifulSoup(html, 'html.parser', from_encoding='euc-kr')
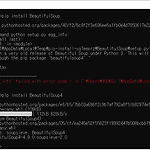 python3.7 pip install beautifulsoup Error
python3.7 pip install beautifulsoup Error
pip install beautifulsoup You're trying to run a very old release of Beautiful Soup under Python 3 "You're trying to run a very old release of Beautiful Soup under Python 3. This will not work.""Please use Beautiful Soup 4, available through the pip package 'beautifulsoup4'." pip install beautifulsoup4
- 소스 코드(3.0기준)#_*_ coding:utf8 _*_ import urllib.request from bs4 import BeautifulSoup fp = urllib.request.urlopen('http://info.finance.naver.com/marketindex/exchangeList.nhn') source = fp.read() fp.close() class_list = ["tit","sale"] soup = BeautifulSoup(source,'html.parser') soup = soup.find_all("td", class_ = class_list) money_data={} for data in soup: if soup.index(data)%2==0: data=data.get_..
 [BeautifulSoup]웹에서 정보 가져오기
[BeautifulSoup]웹에서 정보 가져오기
Python에는 requests라는 유명한 http request 라이브러리가 있습니다. 설치하기(pip로 간단하게 설치가 가능합니다.) pip install requests Requests는 정말 좋은 라이브러리이지만, html을 ‘의미있는’, 즉 Python이 이해하는 객체 구조로 만들어주지는 못합니다. 위에서 req.text는 python의 문자열(str)객체를 반환할 뿐이기 때문에 정보를 추출하기가 어렵습니다. 따라서 BeautifulSoup을 이용해야 합니다. 이 BeautifulSoup은 html 코드를 Python이 이해하는 객체 구조로 변환하는 Parsing을 맡고 있고, 이 라이브러리를 이용해 우리는 제대로 된 ‘의미있는’ 정보를 추출해 낼 수 있습니다. 설치하기 BeautifulSoup..